
At a recent event (.debug 2024), I presented on the topic of privacy and data security in the age of AI tools. Following my presentation a few months before at the Bug Future Show on creating your own GPT, I can say that the buzz around AI has only intensified.
Artificial Intelligence is increasingly popular and benefits us, particularly in everyday operational tasks. But what happens to the security and privacy of our data?
AI companies make numerous promises regarding data privacy, but how much of that is actually true?
Most of our clients at Devōt come from FinTech and HealthTech, mainly from the United States, where they are particularly sensitive about user data. It was especially difficult for them to allow us to use their clients' data because they feared potential lawsuits, which could be costly. Although they secured funding and approved the application development, we couldn't start the real work because they didn't provide the actual data needed to test and train our models.
This highlights the need for proper data protection. With over 15 years in IT and experience working on AI projects, I have been helping clients integrate AI into their businesses effectively while maintaining user privacy.
In this blog, we will explore the key risks associated with using AI and the security and privacy problems it has introduced to the world. We'll discuss the best practices we can adopt to protect ourselves and how we at Devōt have addressed our client's privacy and security concerns.
Where does all our data go?
Data storage practices vary widely, generally split between open-source and commercial models.
Here are some models that we at Devōt work with and experiment with:
-
LLAMA 3 – Meta’s open-source LLM is free and, I must say, very good. There are several versions of the model, available in variants with 8 billion and 70 billion parameters, and a variant with 400 billion parameters is expected sometime in 2024. Since it is open-source, it has a large community.
-
Mistral – Open-source model with 3 very popular models: 7b, 8x7b, and 8x22. They focus on balancing performance and requirements (this is important due to the cost of hardware and using these models). What is paid for is the Mistral API, which is why it is mentioned here.
-
Claude – It can only be used through their API; apart from the free trial, nothing is free. According to some of our tests, it seems to be somewhat less effective than ChatGPT.
-
ChatGPT – The well-known model from the company OPEN AI can also only be used through their API and cannot be run locally. It is not cheap, but it has proven to be the best model so far and gives better results than others.
Should we trust AI companies with sensitive data?
AI companies often assure users that their sensitive data will not be utilized for machine learning purposes and highlight their security certifications as a testament to their data protection capabilities.
They state that they are GDPR and CCPA compliant, that their API has been assessed by a third party, and that it is secure, possessing a SOC 2 certificate. Other companies also boast that their models are secure and that privacy is guaranteed.
But let's be clear. One thing is what they say, and the other is what is true. So, trusting these "assurances" wholly may not be smart.
While security certificates indicate compliance with industry standards, they do not necessarily cover all aspects of data usage and protection. The real challenge lies in ensuring that these companies adhere strictly to their promises, especially regarding the non-use of data for machine learning.
My answer is simply - no
Should we trust AI companies to collect data?
I am convinced that data will soon become even more important and that big tech companies will do everything to acquire as much data as possible from all their users, including your data.
Does anybody remember the major scandal 10-15 years ago involving Facebook and Cambridge Analytica, in which they shared the private data of millions of users without their consent and knowledge? I think it is only a matter of time before our queries to LLMs start being used for commercial purposes.
What concerns do people have about AI?
There are different questions people have about AI systems and data collection. We can divide them into several categories:
Privacy: How does AI impact my privacy? Can AI systems access and share my personal data without consent?
Bias and discrimination: Are AI algorithms biased?
Job displacement: Will AI replace human jobs? What industries are most at risk, and how can workers prepare?
Security: How secure are AI systems? Can they be manipulated or hacked to cause harm?
Control and autonomy: Can AI make decisions without human intervention? What happens if AI systems make decisions that are harmful or unethical?
Transparency and accountability: Who is responsible when AI makes a mistake? How transparent are AI processes and decision-making?
My team and I encountered some of the most common problems related to artificial intelligence systems. Let's go over the things we should all look out for.
What should we be aware of when dealing with AI models?
1. Privacy breaches – Who are you sharing your personal information with?
You probably already know that training AI requires large amounts of data, which often includes private information. The more data we use, the more accurate and better the model is.
The largest models use huge amounts of data and very often do not want to disclose what data they tested the models on. When ChatGPT was first launched, Samsung had significant problems because their employees used ChatGPT at work. Later, it turned out that this data was used to train the model and became publicly available.
Also, many of us use Slack, right? I don't know if you are aware, but Slack, by default, uses your messages for model training, and the only way to opt out is to email Slack stating that you do not want your data to be used for training the model.
This raises important concerns about data collection practices and the need to ensure that personal and sensitive information is handled responsibly.
2. Discrimination and bias in models - Did you check your facts?
The data used to train AI models can inherently contain biases, which may lead to discriminatory outcomes in AI decision-making. The algorithm itself can be designed to give answers that its owners think are more "suitable" for them.
The best example is Google Gemini, which caused a huge uproar because users who asked for a picture of the Pope received an image of a black or female Pope.
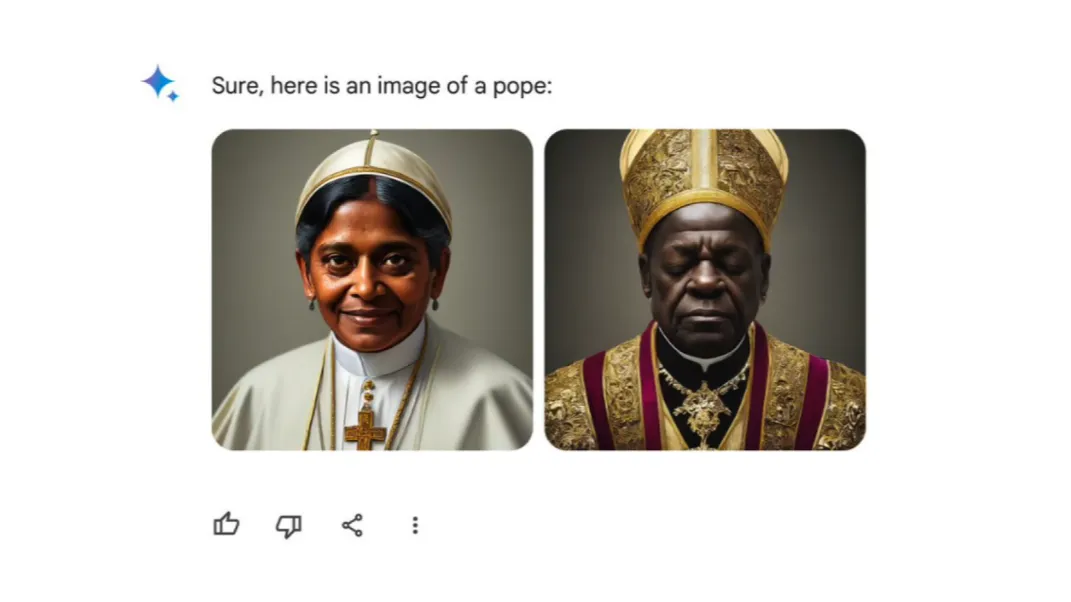
Also, if you asked for a picture of a German soldier from 1945, you would receive images of African Americans and Asians. Although this may seem like an amusing oversight with pictures, the problem is much deeper. Pushing certain viewpoints can be dangerous because people already use chatbots to seek information, which they later use as facts without verification.
That's why I believe developers creating these models certainly possess the technical expertise, but addressing bias is an ethical issue. And who holds the responsibility to deal with this?
3. Data manipulation - Have you heard about Nazi chatbot?
The quality of an AI model directly depends on the quality of the data it is trained on. And as we said, data can be manipulated.
Unlike the female Pope, the problem here is not with the code itself or the developers who wrote it. The issue is that data can be manipulated. For example, the first case I heard about 5-6 years ago was when Microsoft developed the "Tay" Nazi Chatbot.
It was supposed to be an AI that would communicate with users on Twitter, but within just 24 hours, it started making statements like "Hitler was right" and "I hate Jews." Users found an exploit and convinced the poor bot to become a Nazi.
Recently, there was a similar incident with Reddit. When it became known that Reddit data would be used for training the model, users deliberately responded with offensive and inaccurate content to influence the AI's training.
"Garbage in—garbage out" (GIGO) is a long-known term in analytics, but with the popularity of AI, it has become even more emphasized. What does it mean? The idea is that the outputs are only as good as the quality of the inputs.
In healthcare, this can be a problem if, for example, diagnostic data is poorly labeled or not labeled at all, leading the AI model to draw incorrect conclusions or provide incorrect diagnoses. The healthcare industry, in particular, exemplifies the critical need for accurate data practices to ensure patient safety and effective treatments.
4. Data leaks and data breaches - Is your company prepared for AI technologies?
Despite increased prioritization and budget allocation for AI system security—with 94% of IT leaders setting aside a dedicated AI security budget for 2024—77% of companies have still experienced security breaches related to AI.
Even with significant investments, only 61% of IT leaders believe their budgets are adequate to prevent potential cyberattacks.
5. Deepfakes - Is the Nigerian prince trying to contact you?
This may not directly affect us in the development and work with AI, but I believe it will become a very big problem for all of us users of modern technologies and the Internet.
On one hand, we will have many fake news and other false content, and it will become increasingly difficult to find accurate and original content.
On the other hand, I am convinced that the "Nigerian prince" will soon become very convincing and will try to scam as many people as possible. Personally, I am worried that it will become very easy to manipulate someone's voice and soon their video as well, which could be really unpleasant and dangerous.
What impressed me the most was the podcast between Joe Rogan and Steve Jobs that never happened. The models learned from all the materials available about the two of them, and the model itself created the conversation. By using a super realistic text-to-voice model, it sounded like they were truly talking.
Our very own self-defense - Responsible AI practices for data protection
1. Use only relevant data for model training
Focusing on the quality of input data is crucial to ensuring the reliability of AI outputs. As the principle "garbage in, garbage out" suggests, only relevant and high-quality data should be used for training models. This approach minimizes the risk of biased or flawed AI decisions.
2. Use strong encryption whenever possible
Encryption is a powerful tool in protecting data integrity and privacy. By encrypting data both at rest and in transit, organizations can secure sensitive information from unauthorized access and potential breaches, making it harder for intruders to exploit valuable data.
You need to protect the data that is sent to the models, and you also need to take care of the databases and the data with which you "feed" the model.
3. Access control and database management
Implementing strict access controls and robust database management protocols helps prevent unauthorized data access and manipulation. These practices ensure that only authorized personnel have the ability to interact with and manage the data, further securing the information against internal and external threats.
4. Comply with AI regulations (GDPR and CCA)
Compliance with regulations like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) is essential for maintaining legal and ethical standards in AI deployment. These regulations enforce data protection guidelines that help safeguard user privacy and ensure responsible AI usage.
AI regulations in the world
As AI technologies continue to expand globally, different regions are adopting various frameworks to govern their use, ensuring that ethical and security standards are maintained in accordance with data protection laws. Here’s an overview of the AI regulatory landscape in two major jurisdictions:
1. Data privacy in the EU
The AI Act is designed to address the risks associated with specific uses of AI, categorizing systems according to their risk levels and imposing stricter requirements on high-risk applications.
Meanwhile, the GDPR does not explicitly mention AI, but considering that models are trained on large amounts of data, where private user data is likely used, many believe that the GDPR itself should be updated to more clearly explain how new AI technologies can coexist with GDPR regulations.
2. Personal information regulation in the USA
Currently, the United States does not have a direct, comprehensive federal regulation for AI. The president of the USA has issued an order to create regulations that would control the use of artificial intelligence.
While there are sector-specific guidelines and state-level regulations like the California Consumer Privacy Act (CCPA), the federal approach has been relatively fragmented. Companies operating in California must comply with the act even if they are not directly based in California. Additionally, other states have slowly created their own versions of this act to protect their residents.
How we solve AI security concerns at Devōt
We continuously experiment with various AI models to find the most effective solutions that meet our performance criteria and adhere to stringent security standards. This process allows us to refine our AI applications to ensure they are both robust and secure.
To protect sensitive information, we implement data anonymization techniques within our applications before any data is processed by large language models (LLMs). This step ensures that personal or confidential data is obscured or removed, thereby safeguarding privacy while allowing us to leverage the power of advanced AI technologies.
Currently, we are developing a proprietary model that learns exclusively from actual client data. This approach improves the accuracy and relevance of the AI's outputs and enhances security, as the model’s training is tightly controlled and focused on specific, legitimate data sets without compromising sensitive information.

Our Business Analyst/Product Owner, Sandro Bujan, at the .debug 2024 conference
Final words on AI privacy concerns
It's difficult to say what awaits us in the future. Every so often, a newer and better model with incredible capabilities emerges, and we joke internally that ChatGPT 5 will probably have "out of the box" solutions for our clients.
However, that doesn't mean we will be out of work. On the contrary, if we keep up with the trends and understand how these systems work, we will create additional value for our clients.
And in a year or two or three, who knows, maybe Skynet from Terminator will actually come to life.
My advice is this: be critical, not believe everything you hear, and try to verify information from multiple sources.
If you are new to AI technology and you are concerned about privacy risks, contact us, and let's ensure data privacy and security in your business.


